
Are you curious about how to learn to play piano with AI? Then you're at the right spot! Technology is revolutionizing education, especially in 2024... and piano learning is no exception. MuseFlow is currently the best, offering a new innovative app that makes learning piano fun, efficient, and personalized. Check out these 4 reasons why this new app is the best to help you learn to play piano with AI!

People who are learning how to play piano LOVE MuseFlow. One of the main reasons why is the AI-driven personalization. This is amazing because it makes sure that your learning experience is tailored specifically to your unique needs. As you might know, traditional piano lessons follow a generic (and often boring) approach. The piano AI app uses advanced algorithms to analyze your progress and adjust the difficulty level accordingly. This means that whether you're a beginner struggling with basic notes or an advanced player refining complex pieces, the software adapts to keep you challenged but NOT overwhelmed. This keeps the learning experience fun and not frustrating.
This personalized should answer the question "Is there a way to learn to play piano with AI?" with a strong YES. The AI monitors your playing style, identifies areas for improvement, and provides custom exercises to help you progress faster than with conventional methods. This level of customization makes learning a lot faster and also more enjoyable.

One of the most important aspects of a successful learning app is its design, yes it's that important! MuseFlow excels in this area with its immersive and user-friendly interface... The app's design is both visually appealing & functional. This provides a pleasant learning environment that keeps distractions away. The intuitive layout makes it easy to navigate through lessons, practice sessions, and progress tracking. The goal is to get you into that beautiful flow state where learning becomes very easy.
The great design philosophy really makes sure that the learning experience is seamless & enjoyable. If you pay close attention, you will see that the colors are thoughtfully chosen. The clean user-interface helps maintain your focus on playing, allowing you to fully immerse yourself in the music. This exact attention to detail in the design increases your ability to learn and enjoy the process. No other apps on the market, makes learning piano with AI so easy! Just look at the screenshot below.


The Los Angeles based engineering team made learning piano into an engaging and interactive game. They integrate gamification deeply into the learning process. Each new rhythm and note is a level you need to pass, and your performance is tracked in real-time with color-coded notes and a scoring system. Just how you want to keep playing a video game is how you want to keep playing the piano.
Another great feature is that the software gives immediate feedback on accuracy and tempo. This turns practice sessions into a fun challenge. This approach also keeps you motivated and eager to improve.. and this makes it easier to stick with your practice routine. By making the learning process feel like a game, the AI tech answers the works better than a traditional piano teacher. That's why so many users call MuseFlow the best piano learning app.

MuseFlow offers a wide range of tools & features to support your piano learning journey. The app provides quick tutorials before each level, ensuring you understand the key concepts and techniques needed to succeed. Real-time feedback with pattern recognition algorithms. This helps you identify and correct mistakes instantly, allowing you to improve quicker that traditional lessons!
Moreover, MuseFlow is continually expanding its features to provide even more value... Planned updates include advanced curriculum options, AI-driven pattern recognition for even deeper personal insights, and new practice modes for ear training. These comprehensive tools support your journey and make sure that you develop a well-rounded skill set - from technical proficiency to musical understanding.

In conclusion, if you're wondering how to learn to play piano with AI, MuseFlow is the best app on the market. As mentioned above, its AI-driven personalization, engaging gamification, immersive design, and comprehensive learning tools create the best possible learning experience in 2024. MuseFlow makes learning piano not just effective but also really really fun and enjoyable. We promise it will keep you motivated and accelerate progress quickly.
Try the Piano App right now for free
Are you looking to learn piano in a fun, engaging, and effective way? Then you have found the perfect solution! In 2024, the best piano learning app is MuseFlow. This innovative app combines technology with a very deep understanding of musical education like no other. Below are 5 quick reasons why MuseFlow is the best software for learning piano this year.
Try MuseFlow for Free Right Now
The California based company stands out due to its AI-driven personalization. It tailors each lesson to your specific skill level. Traditional piano lessons often follow a one-size-fits-all approach, which can often leave students feeling frustrated or bored. MuseFlow, on the other hand, uses sophisticated algorithms to continuously adapt to your unique progress. Whether you’re just a beginner or an advanced player, the technology makes sure that each lesson is perfectly suited to your current abilities. This will keep you challenged and engaged, and also won't leave you frustrated.

One of the most unique aspects of MuseFlow is its gamified learning experience. The piano app transforms the process of learning piano into a fun game! This means each new rhythm and note you learn is a level you need to pass. Unlike other outdated apps that rely on superficial stars and badges, here the gamification is deeply integrated into its teaching method. This could not be done by a human teaching you piano lessons... Every note you play counts towards your overall score - with real-time feedback that shows your accuracy and tempo. This new engaging approach makes practice sessions feel like a lot of fun & like a rewarding challenge rather than an annoying chore!

Learning an instrument should be an enjoyable experience. MuseFlow's design really reflects that. The app has an immersive &visually appealing interface that makes practicing a pleasure and fun. Unlike other apps with outdated and often complex designs, the best piano app on the market has an interface that is both beautiful and user-friendly. The carefully curated colors, icons, and layout are designed to be easy on the eyes. This is actually really important to staying on the app and enjoying to learn to play piano! It allows you to focus on your playing without distractions. This attention to detail in the design enhances the overall learning experience, making it more enjoyable for you..just look at the screenshot below.

MuseFlow prioritizes sight reading. This is a crucial skill for any pianist. Sight reading is the ability to read & play music at first sight - representing the "floor" of your musical ability. Many traditional teaching methods focus heavily on the "ceiling" of a student's ability—what they can achieve with extensive practice. This AI Piano learning app emphasizes improving your sight reading skills. It really allows you to reach true musical fluency faster. By mastering sight reading, you can quickly progress to playing songs with greater musicality & expression.It makes the learning process more enjoyable and less frustrating...
Another great bonus of the software is that is has an innovative way to generate an infinite amount of new music at YOUR level. This means you will always have fresh material to practice, ensuring that your skills continue to improve without the monotony of repeating the same exercises. This is huge, because all other apps only have the same material you can practice.

This new app is not just about playing notes... it offers a comprehensive suite of tools to enhance your musical education. What does that mean? Well, the app includes tutorials before each level to really make sure that you understand the key concepts & techniques. Real-time feedback from pattern recognition algorithms helps you identify and correct mistakes instantly. This helps you learn faster. Moreover, MuseFlow is continuously expanding its features, with plans to introduce advanced curriculum options, AI pattern recognition for deeper insights, and new practice modes for ear training, chord and scale exercises, and rhythm drills.
The software will soon feature a repertoire library where you can apply your sight reading skills to your favorite songs, and a music theory section with personalized exercises to expand your knowledge.

In 2024, MuseFlow is the best piano learning app available for many reasons! It offers you a unique blend of AI-driven personalization, smart gamified learning, immersive design, helps you focus on sight reading, and offers comprehensive learning tools. By combining these unique elements, the app provides you with a fun, engaging, and highly effective way to learn piano. The best part is, whether you’re a beginner looking to start your musical journey or an experienced player trying to refine your skills, MuseFlow is your best friend to help you achieve your musical goals.
Let’s explore what it means to find the joy in learning a new instrument, and ask ourselves is there a fun way to learn piano? We’ll talk about what it looks like to have fun while you learn an instrument, and explore some options to enhance the process for any student.
If you’re interested in trying out our piano education app for yourself, please visit beta.museflow.ai and try MuseFlow for free! Otherwise, continue reading to find out what it’s all about.
Flow state is a radical idea coined by the Sociologist and Author Mihaly Csikszentmihalyi. It’s that groove you get into where you're doing a task and you lose track of time. The task is usually just a bit of a challenge, but not too challenging that you feel overwhelmed by the task; just hard enough to keep you moving forward and easy enough to know you’re doing well. A lot of professional athletes and musicians find flow in their work, but we at MuseFlow believe we can also tap into it during the learning process. Even for beginners!

Gamification is the application of game-like elements to anything from teaching and learning, to motivating yourself to to the dishes. The old world way of adding game-like elements to an activity involves points and score cards, badges and stars. At MuseFlow, we’ve changed it up a bit by making the entire activity of learning how to play piano a game; not with superficial stars and badges, but by making each new rhythm and note you learn a level that you need to pass.

Once you’ve completed 4 phrases at 95% accuracy at the goal tempo of the level, you pass that level! And are moved onto the next.

This creates an entirely new and fun way to learn piano; not with superficial badges and stars, but by having gamification at the core of the entire method.
Not a lot of people think about this, but design is incredibly important in making the learning process a success. A stark, boring, bright environment, we’ve found, is not the optimal setting to learn music. Because of that, we’ve made our interface beautiful.
We care deeply about the experience our users go through while exploring and learning with MuseFlow. Thus, we’ve made it a tenant of ours to make everything in MuseFlow as beautiful as possible.

Sight reading is the act of reading music at first sight. There are two thresholds in music education - one is what you can play without any practice, the other is what you can play with an indefinite amount of practice. We call the first one the “floor” of your ability, and the second one the “ceiling” of your ability.
Too many teachers and music education methods focus on the ceiling of a student's ability. We at MuseFlow, instead, think a more fun way to learn piano is by focusing on the floor of a student's ability during lessons. Increasing a student's sight reading skill gets them to perfecting the musicality of songs (the fun part of playing songs) faster, instead of spending hours and hours on the technique of simply being able to play the song. That gets boring quickly. It gets frustrating, and students drop out of music lessons because of it.
About 50% of music students drop out of music activities by the time they turn 17. We aim to make that number much smaller.
There hasn’t ever been a way to generate an infinite amount of music at your level of playing… until now. We at MuseFlow have invented a way to give you music you’ve never seen before, that never repeats, and is at your level. The music continues to generate until you get 4 phrases of music at 95% accuracy. At that point, you’ve successfully mastered that new skill!
Sight reading is the key here. We’re teaching through sight reading, instead of teaching through songs. After you’ve mastered that new skill through sight reading, you then can apply that skill to songs that get unlocked in your repertoire section inside of MuseFlow.
These are the reasons why MuseFlow is quickly becoming the most fun way to learn piano. Its inventive way of blending sight reading, flow state, gamification, and immersive design allows students to find the joy of learning an instrument better than ever before. With our new approach to music education, we can revolutionize the music education industry for the better.
Try it out for free at beta.museflow.ai. We can’t wait to hear your feedback as we make music education available and engaging to all students!
Greetings to all the passionate music teachers!
As music aficionados, we understand the profound joy of playing an instrument — a pursuit that’s both challenging and immensely rewarding. However, conveying this love to young students can be a different tune altogether.
Today, let’s delve into the art of sight reading and how embracing flow state through sight reading can bring the joy back to the musical journey for beginners.

Mastering sight reading isn’t just about learning new music faster; it makes learning new music more fun. Fluent sight reading shortens the journey to playing notes correctly, leaving more brain space and time to focus on musicianship and expression.
Yet, traditional teaching methods often don’t teach sight reading. They focus on learning new songs instead. As the songs get harder, students’ skills don’t increase at a relative rate. Because they’re only exercising that new skill in that one specific context of that one specific song. It doesn’t become ingrained in them to the point where they can effortlessly apply the new skill when encountering it in a different piece of music.
As the gap widens, students lose motivation as pieces get harder to practice. They then spend hours repeating the same song over and over to perfection, and get bored with the slow progress, never really feeling what it’s like to be perfectly challenged by something to where it’s fun to practice it! With this way of teaching, it’s either too hard or too easy. Never right in the middle.
Enter the realm of flow state, coined by psychologist Mihaly Csikszentmihalyi. It’s that magical state of total focus and concentration, familiar to musicians during jam sessions and concerts. It’s that Goldilocks zone of “not too hard, not too easy.”
What if we applied the concept of flow to beginning music education by making sight reading the engine of learning and mastering a new skill? And what if we’re were able to start a student right where the challenge meets their skill level so that they’re concentrating and engaged for hours, but still enjoying the practice?

MuseFlow emerges as a solution that combines sight reading and flow state. It systematically teaches fundamental concepts through sight reading by ensuring that each lesson consists of new, manageable music at a specific skill level. No repetition. Instead, it’s a continuous stream of never before seen music that challenges and exercises the new skill, pushing them just beyond their comfort zone.
As their teacher, place your students in the lesson that challenges them just enough (accuracy is displayed on screen. You want to keep them right around 85% for optimum flow). Once they hit 95% accuracy and sustain that for four phrases, they’ve successfully mastered that new skill!
MuseFlow will send you weekly progress reports so you can see if they’re practicing throughout the week and how long they spend on each lesson. Once a student passes a lesson, they can immediately apply the new skills they’ve learned to fresh pieces you assign.

MuseFlow reframes the learning process so students can learn a new skill outside of a prescribed song they’d otherwise have to repeat over and over ad nauseam. They learn the new skill in a flow state, creating a positive connection between the new skill and the process of learning. Then when they apply that new skill to music that’s right at their difficulty level, they’ll be able to learn that song much faster, more thoroughly, and more enjoyably. This will allow you, their teacher, to focus on refining the fun parts like musicianship and expression in the songs you assign at their in-person lesson.
Consider this quote Kyle, one of MuseFlow’s current users:
“MuseFlow is like having a gym partner who guides you through a workout they’ve already planned out. I don’t have to spend time or energy coming up with exercises to train and wondering if it’s optimal, I can just follow along and focus solely on execution. There’s such an overload of information when it comes to learning piano that it’s so taxing (especially if you struggle with perfectionism) to come up with a routine alone. MF takes away a little bit of that decision making and it’s honestly so refreshing.”
In conclusion, combining flow state and sight reading opens a window to a richer and more enjoyable learning experience by inspiring and captivating on a fundamental level. With Museflow, we can shift from a song-first approach to the transformative combination of sight reading and a flow state-first methodology.
MuseFlow is empowering music teachers to revolutionize music education from the ground up. We, as teachers, know the benefits of music education. Now let’s bring it to every student we can.
Curious about whether MuseFlow is right for your students? Visit www.museflow.ai/teachers to schedule a demo. With a MIDI keyboard and a computer, you can try out our current version at beta.museflow.ai. We can’t wait to hear your feedback as we make music education available and engaging to all students!
Is your music practice building true fluency, or is it just training muscle memory?
When we think about how to get better at a musical instrument — or any skill-based activity — the natural strategy that comes to mind is repetition. Repeat, repeat, repeat, until you’ve finally mastered it.
This is the tried-and-true method, and is absolutely correct. As a matter of fact, that’s the whole definition of practice — “performing an activity repeatedly or regularly in order to improve or maintain one’s proficiency.”
But we need to be careful with how we approach our practice sessions. If you spend all of your time practicing specific pieces, you will eventually master those songs but you won’t necessarily have gotten better at playing music in general. Effectively, all you’ve done is train yourself to regurgitate an exact sequence of notes, without any variation. An impressive feat, to be sure, but it hasn’t increased your musical fluency at all.
Learning a musical instrument of course requires maintenance and repetition, but we have to be careful that we don’t practice old things so much that we forget to work on new things. If you only ever practice the same things, you never really grow or improve. It would be like attempting to become fluent in English by memorizing a Shakespeare monologue, and nothing else.
Brad Harrison, a composer and educator who runs an excellent music education YouTube channel, insightfully describes the difference between practice and learning. Practice is trying to get better at things you already basically know how to do. By contrast, learning is the acquisition of new knowledge or skills, and the process of becoming familiar with new material. For example, playing through a piece of music for the first time would fall under “learning,” but each repetition after that would fall under “practice.” Both steps are important, but they are focused on very different goals. Regardless of where you are in your music learning journey, it’s essential that you maintain a healthy balance between practice time and learning time.
By making a habit of learning new things, you’ll develop the meta-skill of learning how to learn. This will make you a better musician and will even help you play old repertoire better. You’ll realize that every new challenge is just a puzzle to be unlocked and understood, and you’ll have the confidence to tackle that puzzle.
If you only play the same songs over and over again, you won’t grow or improve. You’ll either get bored and quit, or you’ll get stuck when confronted with a new challenge because you only know how to do what you already know how to do. Even when you do finally master a new song, the satisfaction of learning it will eventually fade away and you’ll feel stuck again. True musical fluency is the ability to quickly learn and master whatever you want, without needing to practice it for weeks or months on end.
This brings me to an idea that I’ve been formulating over the past several years of working with music students. I think that the way we normally think about the concept of one’s skill level in a certain field needs to be expanded.
Imagine that a person’s skill level can be visualized as a vertical range, with a floor and a ceiling. The ceiling represents the level of music that a person could play well, given an indefinite (but not infinite) amount of time to practice. This could be represented by the hardest piece you’ve ever performed at a recital or competition, for example.
Alternatively, the floor represents the level of music a person could play well (not necessarily perfect, but certainly passable) on the first time they ever see it. This activity is what we call sight reading — reading on sight without any prior preparation. This could be represented by the average piece that you could find sheet music for and play today, without much practice.

Any piece of music that’s below the floor of your skill level is well within your ability to play without any practice. Any piece of music that falls somewhere between your floor and your ceiling can be reasonably mastered through dedicated practice — the closer it is to your ceiling, the longer it will take. The amount of time it would take to learn a piece in this range roughly equates to the amount of time it would take to work your way from the floor up to the difficulty level of the piece in question.
Most people spend the majority of their practice time endeavoring to raise their ceiling, tackling ever harder and harder songs that take them weeks, months, or even years to learn properly. This seems like a fine endeavor, at first glance. Ideally, by raising the ceiling of one’s ability, the floor would also rise by the same amount.

Unfortunately, this isn’t what actually happens. A person’s “floor level” is much more difficult to raise than their “ceiling level”, and it doesn’t happen automatically just by practicing more ceiling-level material. As a result, most music students don’t spend nearly enough time working on raising their floor.
The result is that a person’s ceiling moves up at a much faster rate than their floor, creating a wider and wider gap between them. This means that as they start working on more challenging material, each new song they attempt to learn will take longer and longer to master. This happens to everyone — it’s perfectly natural!

Pretty soon, practice sessions have transformed from a fun learning opportunity into a constant source of frustration and stress that takes up all of their time. Students very quickly find themselves too far outside their comfort zone, without the necessary skills to learn increasingly advanced material in a natural, stress-free way.
This is because a musician’s floor level is actually a far more accurate barometer of overall musical competency than mastery of a song that has been meticulously practiced over and over again for months. In other words, a person’s floor level represents their degree of true musical fluency.

Music lessons often focus on the ceiling of someone’s playing ability, but all professional standards for working musicians place much greater emphasis on a minimum floor threshold of musicianship. It doesn’t matter how good you are after weeks or months of practice — it matters how good you are right now, at a moment’s notice.
So it’s important that you take some time to work on pushing your floor up, even though it might seem like the musical material you’re practicing is dropping way down in complexity as a result. It doesn’t mean you’ve gotten worse, it just means that you’re focusing on a part of your musicianship that you don’t normally focus on!
So how does one actually raise the floor of their skill level then? Here are some specific areas of focus that are most helpful in improving overall musical fluency.
These five areas are what I call the fundamental “food groups” of musicianship. I’ll be going into more depth about each of these in future posts.
Building a well-rounded practice routine is important, and methods with which to do so are well-documented. That being said, it is much harder to be intentional about raising one’s floor level than you might expect.
At MuseFlow, we’re building solutions to this very problem. The app guides users through a continuous sequence of sight reading exercises, increasing complexity by one skill at a time. By constantly playing new material that they’ve never seen before, MuseFlow users have a unique opportunity to hone their ability to read and play music fluently.
In this way, our curriculum ensures a balanced approach between practice and learning. It guides you through a variety of musical challenges, preventing you from getting stuck repeating the same pieces over and over again. This diversity cultivates a well-rounded skill set, and raises the overall floor of your musical ability.
While our main focus is currently on sight reading training, we have lots of exciting new features coming later this year, including technique, music theory, and ear training exercises, as well as a repertoire library and practice assistant. Stay tuned for more updates about all that and more, coming soon!
If you’re looking for a practice tool to help you improve your musical skills, and haven’t been able to find a system that truly delivers the results you’re looking for, consider trying out MuseFlow. Just head on over to https://museflow.ai to sign up for our web app and start your 2-week free trial today.
It’s time to break free from the frustrations of repetitive practice and finally achieve the level of musical fluency you’ve been striving for. Happy playing!

Have you ever felt frustrated or bored while learning to play an instrument? This usually happens because students don’t always feel like they’re in flow state when practicing and learning — that mental zone where time seems to vanish and you become utterly absorbed in the activity. Learning to play an instrument isn’t just about mindless practice; it’s a complete brain workout! Sometimes, the mental gymnastics required to master an instrument can be challenging, pushing students to their limits.
Today, let’s delve into the fascinating world of flow state. We’ll discover how it’s reshaping the way students approach learning an instrument, and why it’s vital for nurturing young musicians who often find the journey too difficult or anxiety-ridden.
Mihaly Csikszentmihalyi’s groundbreaking work in his book Flow: The Psychology of Optimal Experience uncovered the concept of flow state. While it’s often associated with professional musicians and athletes, it can be a game-changer for budding musicians too.
Getting into flow state during music education is like unlocking a secret door to peak performance and enhanced learning. It is a state of complete concentration, where the outside world fades away and the music becomes the sole focus. It’s an optimal mental state where creativity and skill meld seamlessly, leading to a truly immersive musical experience. Flow typically occurs when the challenge of a task matches a student’s skill level. When the challenge is too low, a student might feel bored, and when it’s too high, they may become anxious.
In the world of music, entering flow state often involves selecting pieces of music that are just challenging enough to stretch a student’s ability, but not so difficult that they become frustrated. This is a lot harder than you might think, given the many variables of musical complexity within a single piece of music.
Traditional early music education isn’t all sunshine and harmonies. In fact, dropout rates among young music students are alarmingly high (~50% before they reach the age of 17). The typical grind of discipline and hard work can turn the sweet symphony of learning into a sour note.
So, how do we keep students engaged and passionate about music? The answer lies in integrating flow state into the early stages of learning an instrument. Positive feedback is also crucial. When students feel tangible progress in their education, they’re more likely to enter flow state. And when they receive praise for their efforts (not their achievements), they’re more likely to create positive feedback loops of internal motivation. This combination makes learning something new deeply engaging and gratifying.
One of the most effective ways of reaching flow state while learning an instrument is through sight reading. Sight reading is the act of reading and playing music at first sight. Sight reading pushes students to train their reading and playing skills without relying on muscle memorization, which often becomes a crutch when practicing a single song repeatedly. If the challenge is in the “Goldilocks zone” of their skill level (not too hard, not too easy), then flow state is engaged.
Sight reading, if personalized to a student’s skill level, allows them to drop into flow, immersing them in the process of learning.

Enter MuseFlow, a web app set to transform how students learn piano, especially in the early stages. Instead of assigning one piece of music which exercises many skills all at once — thus making it hard to isolate practice on a specific technique — MuseFlow guides students through new rhythms and notes in isolation first, then embeds that new skill into the rest of their musical knowledge later on, all while immersing them in a constant stream of new music.
In the first level, students learn how music is written, basic rhythms, their first note, and how that one note is played in both hands. Then, they simply start playing. The metronome sets the pace, a guiding cursor shows the next note, and they play each note on the spot while sight reading.
Rather than playing a passage of music, stopping, then repeating that same piece of music over and over again until it’s perfect, MuseFlow pushes students to keep playing no matter what. Getting stuck on previous mistakes is one of the most common ways for students to get knocked out of flow state and lose motivation. In MuseFlow, new music will continue to appear and help them hone their skills in ever-changing contexts, instead of stopping the flow to go back and repeat music they’ve already played.

This is the heart of flow state — that groove that students find themselves in, where time seems to fade away and the joy of learning takes center stage. It becomes just about passing each level, mastering each small new concept, one by one. They start to recognize those aha moments: “Oh my gosh, I’m getting it! I’m really getting it!” When they eventually pass the level, they experience a rush of dopamine and feel a sense of achievement that propels them forward on their musical journey.

Csikszentmihalyi’s research reveals that being in a state of flow can turbocharge the learning process. It’s not only about making learning more enjoyable — it also boosts information retention. By weaving flow state into MuseFlow, we’re tackling the dropout crisis head-on. When students are deeply engaged in the process of learning an instrument, it boosts their motivation, achievement, and enjoyment of learning.
Curious about what MuseFlow has to offer? Visit www.museflow.ai to find out more. If you have a MIDI keyboard and a computer, try out the beta version at www.beta.museflow.ai. We can’t wait to hear what you think and set out on this musical journey with you!
Side note: This pipeline was created for use in a project I’ve been working on with a few friends called Museflow.ai, where we’re trying to combine flow state, gamification, and (eventually) AI to make learning the piano effortless. Feel free to try out the prototype!
If you’re reading this you’re most likely already aware of AWS’s many useful cloud features which make them one of the leading destinations for cloud native applications. AWS’s about page now simply says that they offer “over 200” services, because even they have stopped counting. Today I’ll be focusing on a combination of services which you may or may not have heard of: Pinpoint, Kinesis, Lambda, Eventbridge, Glue, and Athena. That sounds more like a secret pass phrase than a list of technologies, and maybe it is, because together they unlock the ability to analyze your user data as your users interact with your application—or at least I hope.
My goal in writing this will be to put these services together like lego pieces to arrange a data pipeline that pushed events like logins, sign ups, or really any custom event you choose, to a glue table for you to slice and dice with SQL in Athena. From my understanding of how these services interact with one another, it should very well be possible. I’ll be writing this article in 3 parts:
I’ll be using a combination of two infrastructure frameworks to accomplish my setup: AWS SAM and Terraform. I prefer SAM for developing serverless applications for how easy it makes development and deployment, and I like Terraform for shared infrastructure. Configuration values can be shared between these two frameworks using Parameter Store. This project will require both as I’ll be developing a serverless data pipeline in addition to some other infrastructure.
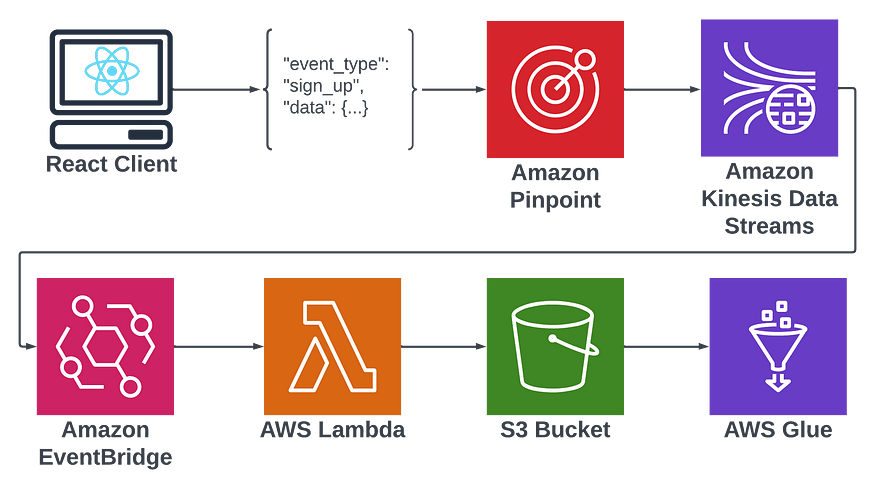
Here’s a quick flow diagram to illustrate the frankenstein of services I will be putting together to achieve this goal:
To quickly walk through the purpose of each service, pinpoint will be used to collect event data. It offers a convenient way to send events from my user’s application to our backend data lake. It offers a plugin connection to Kinesis that I would otherwise have to manually create. Kinesis similarly plugs directly into Eventbridge. Eventbridge acts as a trigger for my Lambda which will map events to correct S3 buckets. The reason I’ll be using different S3 buckets for different events is to provide a separate schema for each. Glue expects all events in an S3 bucket to hold the same schema in order to partition them into a table, which I will then be able to query with SQL using Athena.
Our first order of business is setting up Pinpoint. Since the project I’m setting this up for is a React project, I’ll be showing my frontend client examples in React. The Pinpoint infrastructure setup will be in Terraform.
1resource "aws_pinpoint_app" "pinpoint_app" {
2 name = var.app_name
3}
4
5data "aws_iam_role" "pinpoint_to_event_stream_role" {
6 name = var.pinpoint_role_name
7}
8
9resource "aws_pinpoint_event_stream" "pinpoint_event_stream" {
10 application_id = aws_pinpoint_app.pinpoint_app.application_id
11 destination_stream_arn = aws_kinesis_stream.event_stream.arn
12 role_arn = data.aws_iam_role.pinpoint_to_event_stream_role.arn
13}
14
15resource "aws_ssm_parameter" "client_id" {
16 # checkov:skip=CKV2_AWS_34: Does not need to be encrypted
17 name = "/${var.org_name}/${var.environment}/pinpoint/application_id"
18 description = "Pintpoint application id"
19 type = "String"
20 value = aws_pinpoint_app.pinpoint_app.id
21
22 tags = {
23 environment = var.environment
24 }
25}
26
27resource "aws_kinesis_stream" "event_stream" {
28 name = "${var.app_name}-app-event-stream-${var.environment}"
29 retention_period = 48
30 encryption_type = "KMS"
31 kms_key_id = "alias/aws/kinesis"
32
33 shard_level_metrics = [
34 "IncomingBytes",
35 "OutgoingBytes",
36 "ReadProvisionedThroughputExceeded",
37 "WriteProvisionedThroughputExceeded",
38 "IncomingRecords",
39 "OutgoingRecords",
40 "IteratorAgeMilliseconds"
41 ]
42
43 stream_mode_details {
44 stream_mode = "ON_DEMAND"
45 }
46
47 tags = {
48 Environment = var.environment
49 }
50}This creates an AWS Pinpoint application and an event stream I can use to send Pinpoint Events. Not in the above snippet is the role by pinpoint to send events to Kinesis. I create all my IAM roles in a different, global Terraform workspace specific to IAM. I use template files which inherit variables like account id from a global variables file, but here’s the JSON template I use:
The assume-role policy:
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Effect": "Allow",
6 "Action": [
7 "sts:AssumeRole"
8 ],
9 "Principal": {
10 "Service": "pinpoint.amazonaws.com"
11 },
12 "Condition": {
13 "StringEquals": {
14 "aws:SourceAccount":"${ACCOUNT_ID}"
15 }
16 }
17 }
18 ]
19}
20and the policy attachment:
1
2{
3 "Version": "2012-10-17",
4 "Statement": [
5 {
6 "Effect": "Allow",
7 "Action": [
8 "kinesis:PutRecords",
9 "kinesis:DescribeStream"
10 ],
11 "Resource": "arn:aws:kinesis:us-west-2:${ACCOUNT_ID}:stream/org-name-app-event-stream-dev"
12 },
13 {
14 "Effect": "Allow",
15 "Action": [
16 "kms:DescribeKey"
17 ],
18 "Resource": [
19 "arn:aws:kms:us-west-2:${ACCOUNT_ID}:key/<kms kinesis key ID>"
20 ]
21 }
22 ]
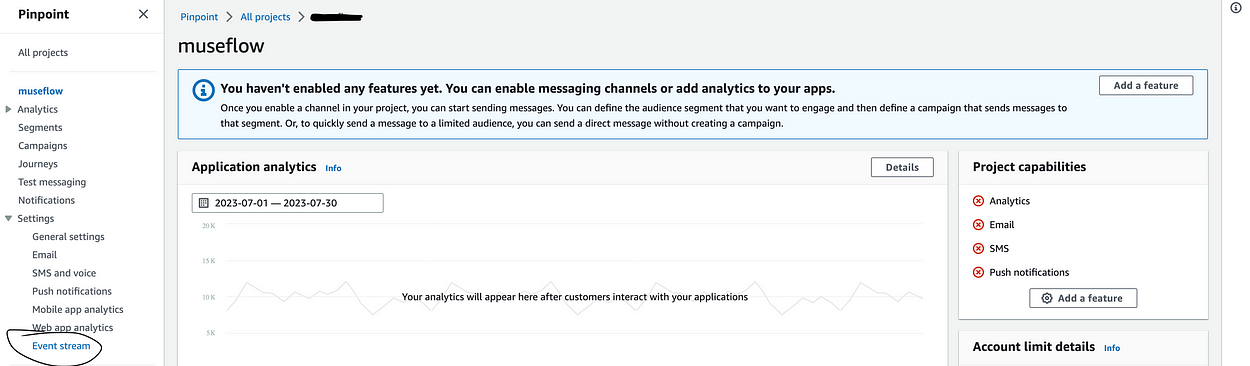
23}Now, once I run the Terraform I can see the following in my AWS console when I navigate to https://us-west-2.console.aws.amazon.com/pinpoint/home?region=us-west-2#/apps.

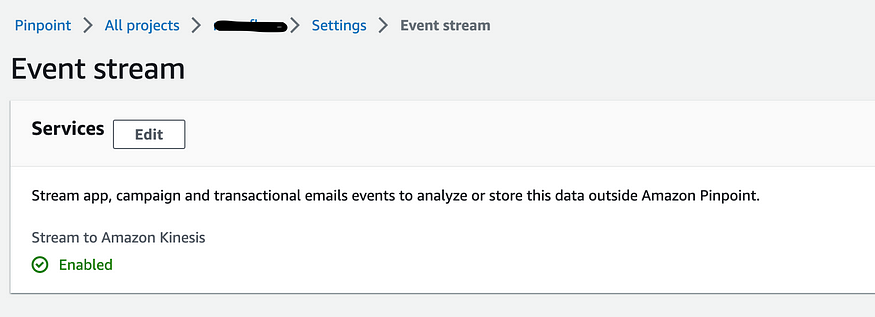
Once you click on the project, the important part is the event stream in settings, which should be enabled.
Now that my event stream is enabled, I can almost start sending events.
Before I can start sending events, my front end needs a way to connect to my AWS resources using AWS credentials. To do that, you need a Cognito Identity Pool. Cognito Identity Pools, not to be confused with User Pools, allow one to provide guests and authenticated users with the credentials needed to access AWS resources. They’re provided permissions like anything else in AWS — with an IAM role. However, the assume role permissions is a bit unique. You’ll be specifying a Cognito identity as a federated identity. Here’s what that looks like:
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Effect": "Allow",
6 "Principal": {
7 "Federated": "cognito-identity.amazonaws.com"
8 },
9 "Action": [
10 "sts:AssumeRoleWithWebIdentity",
11 "sts:TagSession"
12 ],
13 "Condition": {
14 "StringEquals": {
15 "cognito-identity.amazonaws.com:aud": [
16 "us-west-2:<your cognito identity pool id>"
17 ]
18 },
19 "ForAnyValue:StringLike": {
20 "cognito-identity.amazonaws.com:amr": [
21 "authenticated",
22 "unauthenticated"
23 ]
24 }
25 }
26 }
27 ]
28}As you can see, you’re providing the specific cognito identity with permission to assume the role. This can be with anauthorized access — which would be to send events before a user has logged in — or authorized access, which requires a cognito JWT token.
You then give your role permission to send events to pinpoint, by attaching a policy that looks like this:
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Effect": "Allow",
6 "Action": [
7 "mobiletargeting:UpdateEndpoint",
8 "mobiletargeting:PutEvents"
9 ],
10 "Resource": "arn:aws:mobiletargeting:*:${ACCOUNT_ID}:apps/<your pinpoint app ID>*"
11 }
12 ]
13}This is the part that had me confused for a while: you have to specify both unathenticated and authenticated if you want to be able to send sign up events (because the user hasn’t signed in yet). Also, You will need to attach the IAM role to the cognito identity pool for both authenticated and unauthenticated access. Here’s the Terraform:
1resource "aws_cognito_identity_pool" "users" {
2 identity_pool_name = "users_identity_pool"
3 allow_unauthenticated_identities = true
4 allow_classic_flow = true
5
6 cognito_identity_providers {
7 client_id = aws_cognito_user_pool_client.users.id
8 provider_name = "cognito-idp.${var.region}.amazonaws.com/${aws_cognito_user_pool.users.id}"
9 server_side_token_check = false
10 }
11
12 supported_login_providers = {}
13
14 saml_provider_arns = []
15 openid_connect_provider_arns = []
16}
17
18resource "aws_cognito_identity_pool_roles_attachment" "main" {
19 identity_pool_id = aws_cognito_identity_pool.users.id
20
21 roles = {
22 "unauthenticated" = local.identity_pool_role_arn,
23 "authenticated" = local.identity_pool_role_arn
24 }
25}Something to note about the above. Once your user logs in they will switch from an unauthenticated session to an authenticated session which will change the session ID.
I’ll be using the AWS Amplify project to instrument Pinpoint into my frontend code. They provide several useful Javascript libraries for implementing AWS services. If you haven’t heard of Amplify, it’s a framework for developing applications on AWS, similar to Firebase. It’ll get you up and running quickly with AWS infrastructure using Cloudformation. However, I tend to use Terraform for my infrastructure, so I just use the front end libraries they provide.
However, since they intend people to utilize their libraries with Amplify, they can be a bit cagey in the docs with regard to setting it up without Amplify. All of their docs expect you to import the configuration from a file created by the CLI called “aws-exports”, like so:
1import { Amplify, Analytics, Auth } from 'aws-amplify';
2import awsconfig from './aws-exports';
3Amplify.configure(awsconfig);But I don’t really want to do that. Luckily, I was able to find the full expected configuration in one of the library tests which lead me to this config:
1import { Amplify, Analytics} from 'aws-amplify';
2
3Amplify.configure({
4 Auth: {
5 region: region,
6 userPoolId: cognitoUserPoolId,
7 userPoolWebClientId: cognitoClientId,
8 identityPoolId: awsIdentityPoolId,
9 identityPoolRegion: region
10 },
11 Analytics: {
12 AWSPinpoint: {
13 appId: awsPinpointApplicationId,
14 region: region
15 },
16 }
17});I won’t get into the userPoolId and userPoolWebClientId — that’s for Cognito user authentication and could easily be a second post. With this set up, I can then run the following in my sign up function:
1import { Analytics } from 'aws-amplify';
2...
3return signUp(values)
4 .then(result => {
5 Analytics.record(signUpEvent({email: values.email}))
6 })
7 .catch(err => {
8 setAuthErrors(handleAuthErrors(err))
9 });Which uses a defined event function which looks like this:
1export interface EventAttributes {
2 [key: string]: string;
3}
4export interface EventMetrics {
5 [key: string]: number;
6}
7export interface AnalyticsEvent {
8 name: string;
9 attributes?: EventAttributes;
10 metrics?: EventMetrics;
11 immediate?: boolean;
12}
13export const signUpEvent = ({ email }: {email: string}): AnalyticsEvent =>({
14 name: "SignUpEvent",
15 attributes: {
16 email
17 }
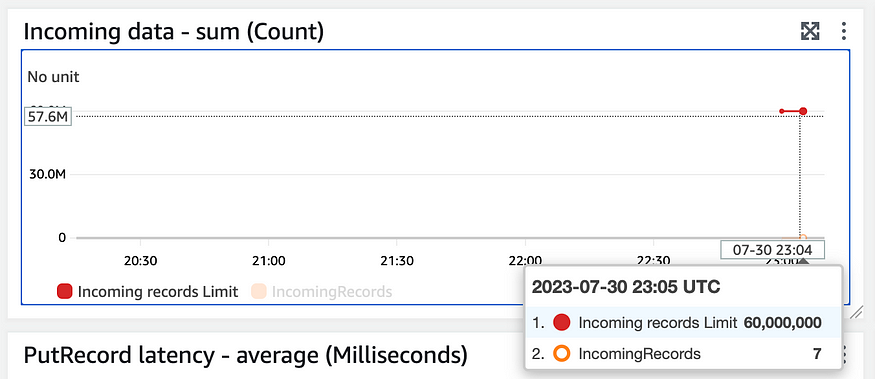
18})Finally, I can see events filtering into the kinesis stream:
Now on to the data pipeline.
In order to sent my events from the pinpoint kinesis stream to S3, I’m going to take advantage of Eventbridge Pipes. Pipes allow you to send events to Eventbridge with additional features like filtering on specific event types and event enrichment. This is the serverless part of the setup, so I’ll be using AWS SAM.
You can install sam with Pip or any of the options here. I’ll be using pip and a python virtual environment. First, I’ll create my virtual env, then I’ll install sam into it.
mkvirtualenv pinpoint-event-pipeline
pip install aws-sam-cliAfter a lengthy install I’m ready to run sam init --name pinpoint-event-pipeline . Or, if you already have a SAM repo setup you like, go ahead and copy everything over.
Eventbridge pipes allow you to filter and enrich events on the way to eventbridge from a variety of source types. One of those source types is a kinesis stream, which is why I chose it for this project.

The following CloudFormation is what I used to create my pipe:
1 Pipe:
2 Type: AWS::Pipes::Pipe
3 Properties:
4 Name: kinesis-to-eventbridge
5 Description: 'Pipe to connect Kinesis stream to EventBridge event bus'
6 RoleArn: !GetAtt PipeRole.Arn
7 Source: !Sub arn:aws:kinesis:us-west-2:${AWS::AccountId}:stream/my-org-app-event-stream-${Environment}
8 SourceParameters:
9 FilterCriteria:
10 Filters:
11 - Pattern: '{"data":{"event_type":["SignUpEvent"]}}'
12 - Pattern: '{"data":{"event_type":["SignInEvent"]}}'
13 KinesisStreamParameters:
14 StartingPosition: LATEST
15 BatchSize: 1
16 DeadLetterConfig:
17 Arn: !GetAtt PipeDLQueue.Arn
18 Target: !Sub 'arn:aws:events:us-west-2:${AWS::AccountId}:event-bus/my-org-events-${Environment}'
19 Enrichment: !GetAtt TransformerLambda.Arn
20 EnrichmentParameters:
21 InputTemplate: '{ "data": <$.data> }'Obviously, I cut a lot of the template out for brevity, including the code for deploying my “enrichment” lambda as well as DLQ and Pipeline role. The full template can be found here.
In the above Pipe resource, I’ve defined a filter that only allows events that I’ve defined to pass through to my lambda — specifically only the “SignUpEvent” and “SignInEvent” event types I’ve defined. I’ve also defined an enrichment lambda — which I’ve called a “transformer” lambda because I’ll be using it to transform events into the format I’d like to have sent to my backend. At first, I just used the lambda to print the event to get an idea of how the data is shaped when it gets to my lambda, and without much time passing, I can see it in my Cloudwatch logs:
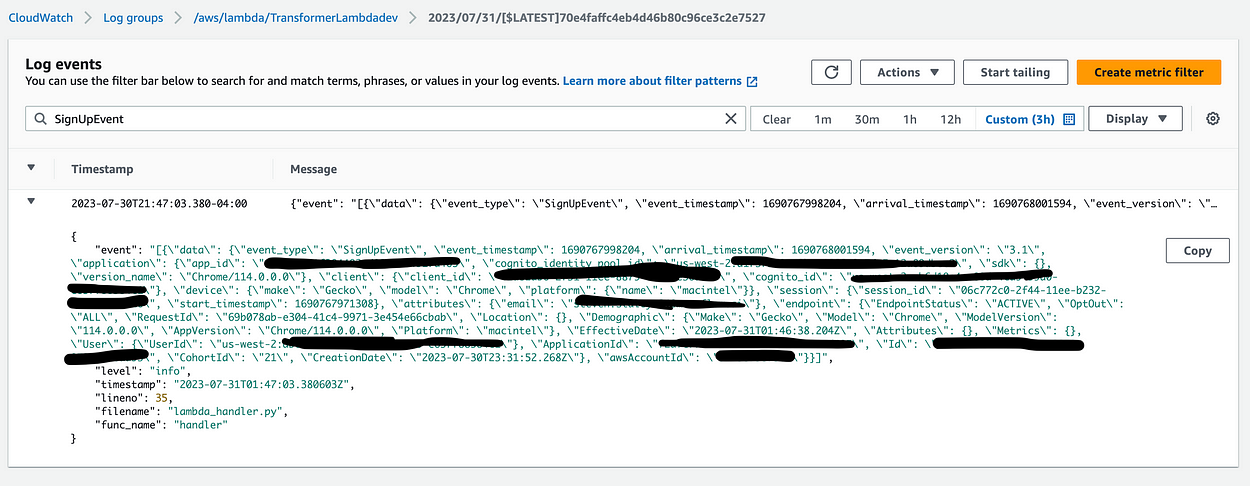
Unfortunately, at this point I hit a wall. I would like to send the event along its way to Eventbridge (see the target of my Eventbridge Pipe). From there I would be able to create a rule which triggers on arrival of sign in/sign up events. Unfortunately, while I’m able to see the events recieved in the Eventbridge metrics — I’m not able create an event rule that triggers. I’m even using the generated schema from Eventbridge’s handy tool which scans your events:

The point of sending the event to event bridge was to create the potential for an event driven approach that would allow me to feed more than one data source from eventbridge. Eventually, if I want to also send data to a realtime database, like Timescale, I would be able to create a second output lambda to route data to that database as well. However, for now my goal is to view my data in Athena. So, instead of routing my event to eventbridge and creating an eventbridge rule to trigger an S3 upload lambda, I’m going to make the lambda the target of my Eventbridge pipe.
This will involve editing the Pipe config like so:
# Target: !Sub 'arn:aws:events:us-west-2:${AWS::AccountId}:event-bus/museflow-events-${Environment}'
# for now - just point to the output lambda instead of pushing to eventbridge first.
Target: !GetAtt PinpointOutputLambda.ArnThere are plenty of tutorials on how to set up a lambda with AWS SAM, so I won’t be going over that here. But, there are some gotchyas in the setting up the event pipe and athena backend. You need to make sure your Pipe has permission invoke each lambda (the validator and the final target), and your lambdas need permission to post to the final S3 buckets which will make up your Athena tables. Your lambda invoke permissions will look like this:
Resources:
TransformerLambdaInvokePermission:
Type: 'AWS::Lambda::Permission'
Properties:
FunctionName: !GetAtt TransformerLambda.Arn
Action: 'lambda:InvokeFunction'
Principal: 'pipes.amazonaws.com'
SourceAccount: !Ref 'AWS::AccountId'
SourceArn: !GetAtt Pipe.Arn
OutputLambdaInvokePermission:
Type: 'AWS::Lambda::Permission'
Properties:
FunctionName: !GetAtt PinpointOutputLambda.Arn
Action: 'lambda:InvokeFunction'
Principal: 'pipes.amazonaws.com'
SourceAccount: !Ref 'AWS::AccountId'
SourceArn: !GetAtt Pipe.ArnIn addition to the above you’ll want to provide the following permissions to the “output lambda” — or the lambda that your Eventbridge Pipe is targeting:
- Effect: Allow
Action:
- s3:PutObject
- s3:AbortMultipartUpload
Resource:
- !Sub 'arn:aws:s3:::museflow-sign-up-events-${Environment}'
- !Sub 'arn:aws:s3:::museflow-sign-in-events-${Environment}'Now, I’ll get a bit into the lambda code. My first lambda has two purposes: Validate the incoming event, and transform the event into a truncated version containing only the necessary pieces. The transformer lambda handler looks like this:
1import urllib.parse
2import os
3import traceback
4from utils.logger import logger
5import json
6from aws_xray_sdk.core import patch_all
7from aws_xray_sdk.core import xray_recorder
8from main.transformer import transform_event
9
10logger.info('Loading function')
11env = os.getenv('Environment', 'local')
12TracingOff = os.getenv('TracingOff', False)
13
14def handler(event, context):
15 log.info(json.dumps(event))
16 log.info(context)
17 env = os.getenv("Environment")
18 s3_endpoint_url = os.getenv('S3EndpointUrl')
19 region = os.getenv("AWSRegion")
20
21 log.info(f"region: {region}")
22 log.info(f"s3_endpoint_url: {s3_endpoint_url}")
23 validated_events = []
24 for evt in event:
25 try:
26 # print(evt['data']['event_type'])
27 transformed_evt = transform_event(evt)
28 json_dict = json.loads(transformed_evt.model_dump_json())
29 validated_events.append(json_dict)
30 except Exception as e:
31 if env != "local" and not TracingOff:
32 subsegment_ref = xray_recorder.current_subsegment()
33 if subsegment_ref:
34 subsegment_ref.add_exception(e)
35 log.exception(e)
36 log.error('failed_to_validate_event', evt=json.dumps(evt))
37 try:
38 return validated_events
39 except Exception as e:
40 log.error(e)
41 traceback.print_exc()
42 raise e # re-raise for Lambda consoleEach event is run through a transformation function called “transform_evt”. That function looks like this:
1def transform_event(event):
2 if event['data']['event_type'] == 'SignUpEvent':
3 return SignUpEvent(**({
4 "event_type": event['data']['event_type'],
5 "datetime": event['data']['endpoint']['EffectiveDate'],
6 "session_id": event['data']['session']['session_id'],
7 "email": event['data']['attributes']['email'],
8 }))
9 elif event['data']['event_type'] == 'SignInEvent':
10 return SignInEvent(**({
11 "event_type": event['data']['event_type'],
12 "datetime": event['data']['endpoint']['EffectiveDate'],
13 "session_id": event['data']['session']['session_id'],
14 "email": event['data']['attributes']['email'],
15 "id": event['data']['attributes']['id'],
16 "is_test_user": event['data']['attributes']['is_test_user'],
17 "user_type": event['data']['attributes']['user_type'],
18 }))Each event is being validated by its respective Model, which I’ve written using Pydantic, a rather convenient python validator. Something to point out in the above model is that I’m using the “effective date” portion of the event as the timestamp. It seemed as good an option as any.
Here’s the model I’m using for my SignUpEvent:
from pydantic import BaseModel, Extra, EmailStr, field_serializer
from datetime import datetime
from typing import Literal
class SignUpEvent(BaseModel):
class Config:
extra = Extra.forbid
@field_serializer('datetime')
def serialize_dt(self, dt: datetime, _info):
return dt.strftime('%Y-%m-%dT%H:%M:%S.%f')[:-3] + 'Z'
event_type: Literal['SignUpEvent']
datetime: datetime
session_id: str
email: EmailStrIn order for an event to be processed it must conform to the expected schema. Additionally, I’m serializing the date to remove the last 3 0's that get appended to the end when Pydantic prints the date into JSON. Something else to note is that The Amplify library which I’m using to send these events doesn’t accept null values. So, to compensate for that I wrote the following validator, which allows for nulls:
1def coerc_string_to_null( string_val: Any):
2 val = None if string_val == 'null' else string_val
3 return val
4
5class MyClass(BaseModel):
6 ...
7 _my_value_validator = validator('my_value', pre=True, allow_reuse=True)(coerc_string_to_null)
8 my_value: Union[str, None)Now, we can discuss what I’m calling the “OutputLambda”, which is responsible for taking the validated and transformed event, and sending it to the Athena backend. After this section I’m going to go over actually creating the Athena backend, but for now it should be noted that there is an S3 bucket for each event type. Here’s the handler code for the output lambda (I’ve removed some extraneous code that’s pretty much the same as the last one):
1def get_date_details(datetime_str):
2 dt = datetime.strptime(datetime_str, '%Y-%m-%dT%H:%M:%S.%fZ')
3 return (dt.day, dt.month, dt.year)
4...
5try:
6 s3_client = boto3.client('s3', endpoint_url=s3_endpoint_url)
7 for evt in event:
8 with tempfile.TemporaryDirectory() as temp_dir:
9 id=str(uuid.uuid4())
10 schema = transform_event_schema(evt)
11 parquet_out(evt, schema, f'{temp_dir}/evt_parquet_{id}.parquet')
12 s3_bucket = bucket_map[evt['event_type']]
13 day, month, year = get_date_details(evt['datetime'])
14 s3_put_object(s3_client, s3_bucket, f'year={year}/month={month}/day={day}/{evt["event_type"]}{id}.parquet', f'{temp_dir}/evt_parquet_{id}.parquet')
15 return {
16 "statusCode": 200,
17 "headers": {
18 "Content-Type": "application/json"
19 },
20 }As you can see I’m calling a new transform function on each event — but this time it’s called transform_event_schema . That’s because I’m taking each event and creating a parquet schema. You can use JSON for Athena, but Parquet is more efficient, which may save you some $$. Here’s the code for my parquet schema generator:
1import pyarrow as pa
2import pyarrow.compute as pc
3
4def transform_event_schema(event):
5 if event['event_type'] == 'SignUpEvent':
6 return pa.schema([
7 ('datetime', pa.timestamp('s', tz='UTC')),
8 ('event_type', pa.string()),
9 ('session_id', pa.string()),
10 ('email', pa.string())
11 ])
12 elif event['event_type'] == 'SignInEvent':
13 return pa.schema([
14 ('datetime', pa.timestamp('s', tz='UTC')),
15 ('event_type', pa.string()),
16 ('session_id', pa.string()),
17 ('email', pa.string()),
18 ('id', pa.string()),
19 ('is_test_user', pa.bool_()),
20 ('user_type', pa.string())
21 ])It’s a bit verbose and frankly, kind of strangely formatted, but that’s the gist. What isn’t pictured here is an example of an int, for which you might use pa.int64() . You can read more about parquet data types here.
Once my parquet schema is created, I can write it to S3. Unfortunately, I couldn’t easily figure out a way to transform the event into parquet and write directly to S3 from memory, so instead I created a file in a temp directory. It’s important to use a temp directory because Lambdas can potentially use the same context with the same temp. The code I used to write the parquet file looks like this:
1from json2parquet import write_parquet, ingest_data
2
3def parquet_out(json_blob, schema, path):
4 # table = pa.Table.from_pydict(json_array, schema)
5 # pq.write_table(table, path) # save json/table as parquet
6 date_format = "%Y-%m-%dT%H:%M:%S.%fZ"
7 record_batch=ingest_data([json_blob], schema,date_format=date_format)
8 write_parquet(record_batch, path,compression='snappy', use_deprecated_int96_timestamps=True)I used a nifty library called json2parquet. The one part that’s worth calling out here is use_depreciated_int96_timestamps=True . From the json2parquet docs:
“If you are using this library to convert JSON data to be read by Spark, Athena, Spectrum or Presto make sure you use use_deprecated_int96_timestamps when writing your Parquet files, otherwise you will see some really screwy dates.”
Fair enough.
The final bit of info worth sharing is that when you write these files to S3 you’ll want to do so in binary. Here’s the function I used to read the parquet file and push it to S3:
1from smart_open import open
2
3def s3_put_object(client, bucket, key, file_path):
4 file = open(file_path, 'rb')
5 content = file.read()
6 tp = {'min_part_size': 5 * 1024**2, 'client': client}
7 uri = f's3://{bucket}/{key}'
8 with open(uri, 'wb', transport_params=tp) as fout:
9 logger.info(f"pushing to s3 {uri}")
10 fout.write(content)
11 file.close()smart_open is utility library which allows you to read and write from S3 like a native file system using the “open” function. As you can see, I’m specifying b for ‘binary’.
And that’s pretty much it. After deploying, I can go log into my app and watch my function invocation metrics:
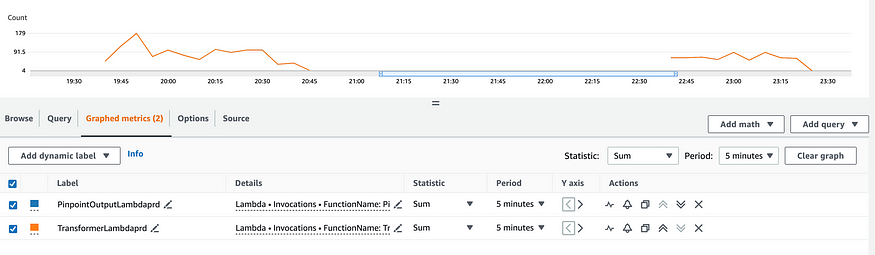
And check out their corresponding evens in S3:
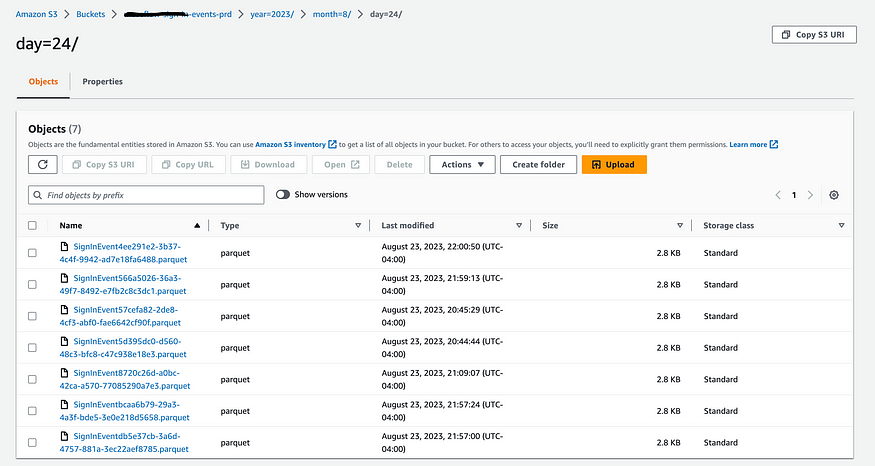
You might have also noticed the slightly specific path I chose for these events. This is actually a way that Glue will partition your tables by date automatically (More info in the AWS docs here), which brings us to our next section: Glue/Athena.
AWS Glue is a pretty nifty tool with a lot of data-centric features. One thing it works well with is Athena — a Serverless query engine that allows you to query against a multitude of sources, one of which being a Glue table.
In order to create Glue tables based on your S3 data, you’ll need to create what’s called a “Glue Crawler” which will read all of your data in an S3 bucket and place it into a glue table. Now, what’s really nifty about these crawlers is that you don’t even have to create the tables yourself. The crawler will infer the schema of your table based on the format of the data in the S3 bucket. You saw the schemas earlier in my output lambda. So, all you need to do is define an Athena database and one crawler per S3 bucket. Here’s the Terraform I wrote to create them:
1locals {
2 glue_role = data.aws_iam_role.glue_role.arn
3}
4
5data "aws_iam_role" "glue_role" {
6 name = var.glue_role_name
7}
8
9resource "aws_glue_catalog_database" "this" {
10 name = var.database_name
11 description = var.database_description
12 parameters = var.parameters
13}
14
15resource "aws_glue_crawler" "this" {
16 for_each = var.tables
17 name = "${var.database_name}_${each.key}_glue_crawler_${var.environment}"
18 description = "${var.database_name} glue crawler for table ${each.key} ${var.environment}"
19 database_name = aws_glue_catalog_database.this.name
20 role = local.glue_role
21 schedule = "cron(0 1 * * ? *)"
22 configuration = jsonencode(
23 {
24 Grouping = {
25 TableGroupingPolicy = "CombineCompatibleSchemas"
26 }
27 CrawlerOutput = {
28 Partitions = { AddOrUpdateBehavior = "InheritFromTable" }
29 }
30 Version = 1
31 }
32 )
33 s3_target {
34 path = each.value.location
35 }
36}
37
38resource "aws_athena_workgroup" "athena" {
39 name = var.aws_athena_workgroup_name
40
41 configuration {
42 enforce_workgroup_configuration = true
43 publish_cloudwatch_metrics_enabled = true
44
45 result_configuration {
46 output_location = "s3://${var.s3_query_result_bucket_name}/output/"
47
48 encryption_configuration {
49 encryption_option = "SSE_S3"
50 }
51 }
52 }
53}Not provided above is the config for the S3 Athena query output bucket. Make sure that when you do create the output bucket, you provide a bucket policy that gives access to athena via “athena.amazonaws.com”. For reference, here are the variables I provided to the above template:
1{
2 "environment": "prd",
3 "database_name": "org_name_analytics_prd",
4 "database_description": "org_name athena analytics db",
5 "glue_role_name": "org_name-main-prd-glue-role",
6 "s3_query_result_bucket_name": "org_name-athena-output-prd",
7 "aws_athena_workgroup_name": "org_name-analytics-prd",
8 "tables": {
9 "org_name_sign_in_events": {
10 "description": "org_name app sign in events table prd",
11 "location": "s3://org_name-sign-in-bucket-prd/"
12 },
13 "org_name_sign_up_events": {
14 "description": "org_name app sign in events table prd",
15 "location": "s3://org_name-sign-up-bucket-prd/"
16 }
17 },
18}In this config each key is the name of a table/crawler. Two things are important to mention. Athena only takes underscores and letters as table names, and you need to end your s3 bucket location with a slash: “/”.
As you can see, I provided a role to be used by the glue crawler. You should make sure that role has permissions to access to each of the S3 buckets you create to hold your parquet events, like so:
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Effect": "Allow",
6 "Action": [
7 "glue:*",
8 "lakeformation:*"
9 ],
10 "Resource": [
11 "*"
12 ]
13 },
14 {
15 "Effect": "Allow",
16 "Action": [
17 "s3:GetObject",
18 "s3:ListBucket"
19 ],
20 "Resource": [
21 "arn:aws:s3:::org_name-sign-up-bucket-prd",
22 "arn:aws:s3:::org_name-sign-up-bucket-prd/*",
23 "arn:aws:s3:::org_name-sign-in-bucket-prd",
24 "arn:aws:s3:::org_name-sign-in-bucket-prd/*"
25 ]
26 }
27 ]
28}Finally, with all this in place I can visit the Athena console and write a query:
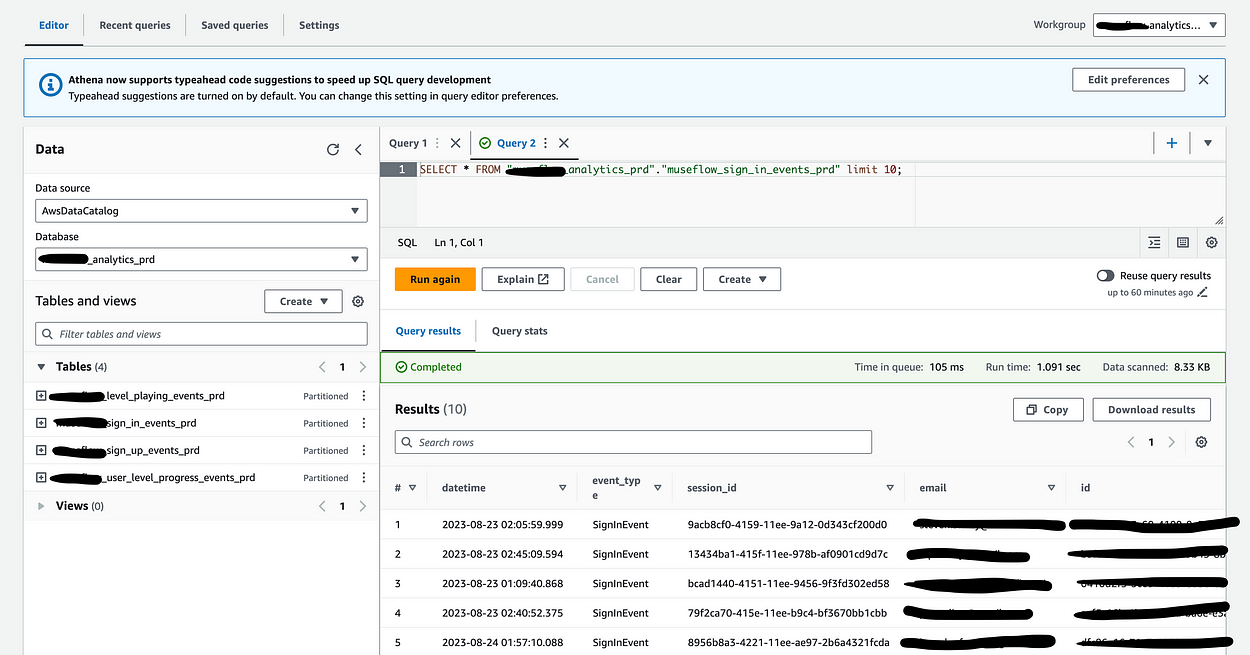
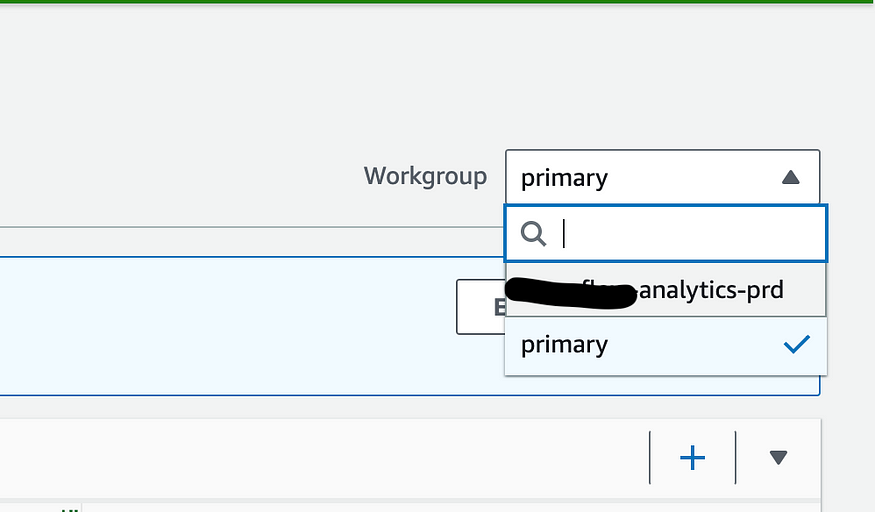
One thing to note is that you should select the correct working group on the top right, because that’s what actually configures the output bucket. Otherwise, you’ll be asked to configure a new one.
This was a fun project. I’ve wanted to set up an Athena pipeline for a while, but never had a good reason. With an easy to create Athena pipeline, I’ll be able to easily and cheaply store data for use in ML, business analytics, or any other analytics I’d like to do.
Some closing thoughts. As you saw in the image of my lambda invocation metrics, this process doesn’t batch at all. That means potentially a single invocation per event. This could potentially get rather costly, so a way to mitigate this might be to place an SQS queue between my event pipe and my lambda. Additionally, Crawlers will re-crawl all of your data daily. This can also be costly, but an alternative might be to use event driven crawlers which would prevent re-crawling of data.
Hope this was an enjoyable and instructive read. If you’d like to follow me for more tech articles, feel free to follow me here or add me on Linkedin: https://www.linkedin.com/in/steven-staley/

Keep up to date on our progress as we continue to add new features!